Disasters don’t follow a schedule. A disaster recovery checklist gives your business a clear roadmap for recovery and ensures you don’t miss critical steps.

Emergency Management Sep 04, 2025
Minimize Downtime With a Disaster Recovery Checklist
Disaster Recovery Plan Template
Prepare for and recover from any critical event your business may face.

When disaster strikes—whether it’s a cyber incident, a natural disaster, or a system failure—a smooth recovery process is critical to getting back on your feet. But recovery doesn’t simply unfold once the immediate crisis ends. Rapid operational recovery starts with planning long before the disaster occurs.
Flexibility is essential in disaster recovery since no event follows a predictable script. The right preparation makes adapting quickly, maximizing limited resources, and minimizing disruption possible. A comprehensive disaster recovery plan is a roadmap for efficiently resuming operations and reducing the impact on the business and its customers.
A great way to begin building—or reassessing—your strategy is with a disaster recovery plan checklist. Whether you’re facing natural disasters, cyberattacks, or technology breakdowns, a checklist provides a structured framework to safeguard your people, your data, and your continuity of operations.
Disaster Recovery Plan Template
Prepare for and recover from any critical event your business may face.
Why Disaster Recovery Planning Matters
A disaster recovery plan (DRP) is a structured document that outlines the procedures, tools, and responsibilities your organization follows during disruptions. It is a core part of organizational resilience, designed to reduce damage, restore systems, and help teams return to normal operations as quickly as possible. Calculating the cost of downtime for your organization illustrates why preparation is essential; lengthy outages can result in significant financial losses and damage your reputation.
Disaster recovery is often confused with business continuity, but the two serve different purposes. Understanding how business continuity and disaster recovery work together can strengthen your resilience strategies.
| Disaster Recovery | Business Continuity |
| The DRP activates once the immediate crisis has passed, focusing on restoring IT systems, applications, and data. Clear recovery time objectives (RTOs) and recovery point objectives (RPOs) set the benchmarks for how quickly systems must be restored and how much data loss is acceptable. | Business continuity plans keep critical processes running during an emergency, using alternate work arrangements, communication protocols, and logistical support to maintain essential services. |
Disasters come in many forms—hurricanes, wildfires, pandemics, cyberattacks, and power outages—and no two look the same. That unpredictability is precisely why a disaster recovery checklist is so important: It gives organizations a step-by-step roadmap that adapts to different situations, helping teams act quickly and avoid missed steps under pressure.
The value of having a checklist becomes especially clear when multiple types of disasters hit organizations in close succession. For example, OneBlood, a major blood supplier serving hundreds of hospitals, was hit by a ransomware attack that shut down its core systems for weeks. Not long after, Tropical Storm Debby brought historic flooding that disrupted deliveries and mobile donation sites.
In cases like this, a checklist provides a unifying framework for managing both crises—first restoring IT systems, then shifting into flood response—without forcing teams to reinvent the process in the middle of chaos.
IT & Cyber Disaster Recovery Checklist
Cyber incidents often require specialized procedures and faster recovery times. Use this mini‑checklist to strengthen your IT resilience:
- Identify critical IT systems and data — List essential servers, applications, databases, and endpoints.
- Assess cyber threats and technology risks — Evaluate potential risks such as ransomware, data breaches, system failures, and network outages.
- Define recovery objectives — Set clear RTOs and RPOs for IT assets, balancing acceptable downtime and data loss.
- Establish data backup and restoration procedures — Establish regular backup schedules, store backups securely offsite or in the cloud, and test restoration procedures.
- Assign IT disaster recovery roles — Designate a disaster recovery team responsible for system recovery and communications.
- Incident response steps — Outline immediate actions for cyber incidents, including containment, eradication, and recovery.
- Alternate IT infrastructure — Plan for failover systems, cloud resources, secondary data centers, or redundant network connections.
- Communication plan — Define protocols for alerting staff, leadership, vendors, and customers about cyber incidents.
- Testing and updating — Perform regular IT-specific drills and update procedures as technologies and threats change.
A Comprehensive Disaster Recovery Checklist
The following fifteen steps outline how a disaster recovery checklist guides organizations through crisis response.
We’ll use the hypothetical example of Riverbend Manufacturing to bring the steps to life:
When severe flooding forced an evacuation and a ransomware attack struck simultaneously, the company turned to its tested checklist. Each step showed the leadership team who to call first, which systems to restore, and how to keep employees and customers informed.
1. Pinpoint your most significant risks before they happen
Every effective disaster recovery plan begins with a clear-eyed understanding of what could go wrong. A risk and impact assessment is your organization’s way of mapping out potential threats—natural disasters, cyber incidents, power outages, or supply chain disruptions—and then ranking them by likelihood and severity.
This process usually includes:
- Risk assessment: Identifying possible events and evaluating how likely they are to occur.
- Business impact analysis (BIA): How those events affect critical processes, such as payroll, customer service, or production.
- Prioritization: Deciding which systems and services must come back online first to minimize operational and financial fallout.
Instead of trying to predict every possible disaster, many organizations diagram the results on a risk matrix, plotting likelihood against impact. This approach makes it easier to see which threats demand the most attention and ensure recovery procedures are focused where they matter most.
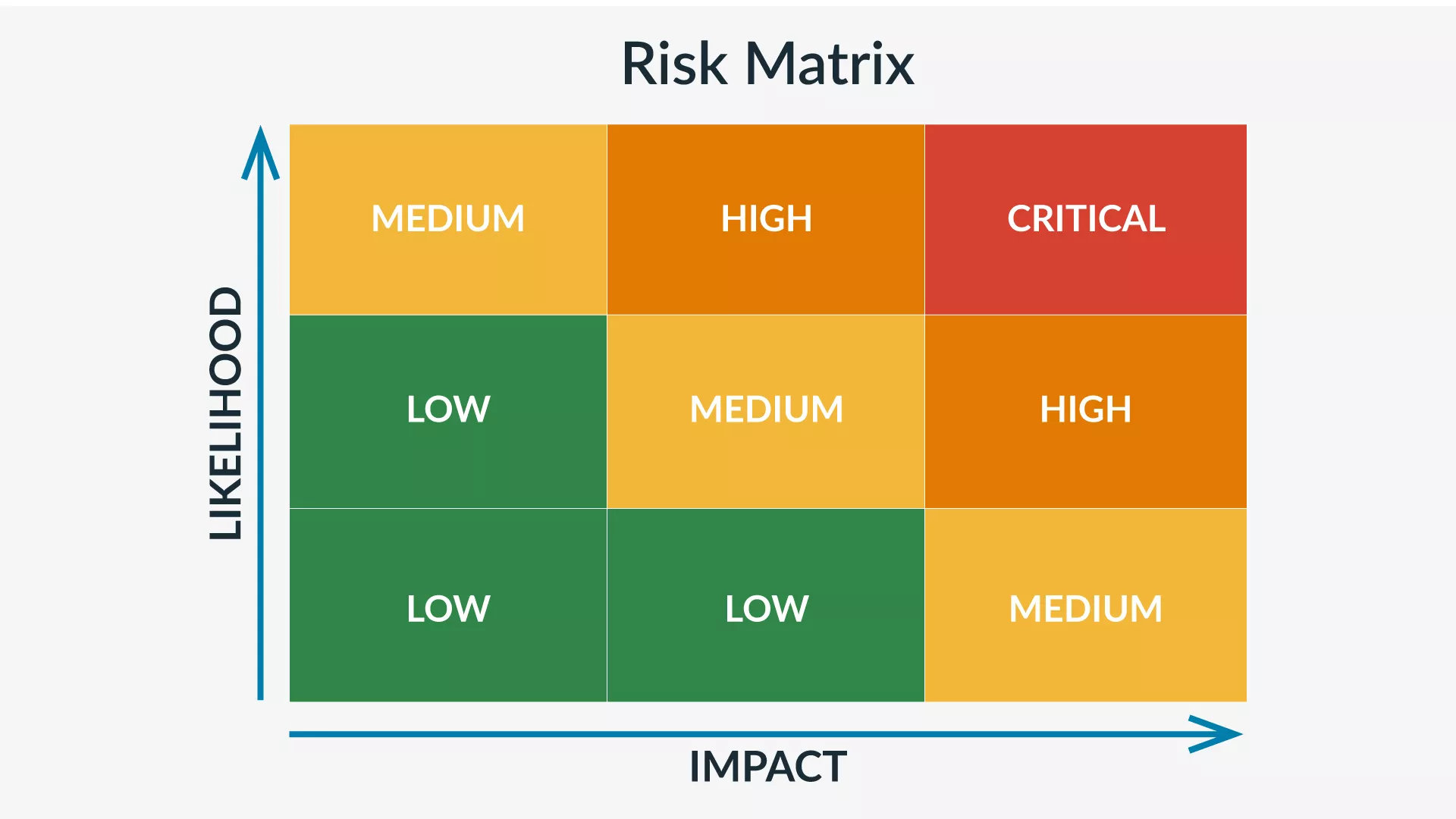
At Riverbend Manufacturing, leadership had recently completed a combined risk assessment and BIA. Their analysis revealed that flooding and cyberattacks were two of the most significant threats to their operations. Floodwaters could shut down production lines and block employee access to the facility, while ransomware could paralyze order processing and financial systems.
By flagging both in the risk matrix, Riverbend was able to prioritize recovery actions for these scenarios. When both struck at the same time, the team already had clear guidance on what to do first.
2. Rally Every Department and Stakeholder
No disaster recovery plan succeeds in isolation. It’s not one department’s responsibility to ensure operations rebound; every department has a role to play, from facilities and HR to security, compliance, IT, and communications. By bringing all those groups into the planning process early, you prevent silos from slowing down response when time matters most. External partners, like vendors, regulators, and even local emergency officials, must also be mapped into the plan to engage without delay.
At Riverbend Manufacturing, this coordination made all the difference. As floodwaters rose and systems went offline, the safety officer evacuated employees, while the IT manager triggered the cyber response remotely. Because roles were defined and stakeholders identified ahead of time, the transition from physical evacuation to digital containment happened in parallel, turning what could have been chaos into a synchronized response.
3. Turn past crises into future strength
Every disaster recovery plan should evolve with experience. Reviewing past emergencies, whether they happened inside your organization or to a peer in your industry, reveals what worked, what failed, and where blind spots exist. These lessons are often the difference between stumbling through a repeat mistake and executing a faster, smoother response.
Plan reviews should not happen only on a fixed annual schedule. Any major business or technology change—such as migrating to new software, opening a new facility, or restructuring departments—can create new vulnerabilities. Reviewing and updating your disaster recovery checklist after these shifts ensures it reflects current realities, not outdated assumptions.
At Riverbend Manufacturing, a previous winter storm had exposed gaps in communication. Messages were delayed, updates were inconsistent, and employees were left uncertain about the next steps. By folding those lessons into their updated checklist, Riverbend established clearer communication protocols, so when the flood and cyberattack struck together, information flowed quickly and confidently.
4. Define roles and backups before disaster hits
Clear leadership prevents a response from spiraling into confusion. A disaster recovery plan should spell out which team members will lead, communicate, protect people, and keep operations moving. The plan should also identify backups in case someone is unavailable.
Key roles often include:
- Incident commander — Takes overall charge, makes decisions, and coordinates the response.
- Communication coordinator — Manages internal and external updates, ensuring clear, timely information.
- Safety officer — Monitors hazards and enforces safety measures during the event.
- Medical responder — Provides immediate care and connects with emergency services.
- Evacuation coordinator — Directs safe, orderly evacuations, accounting for all personnel.
- Operations manager — Keeps essential business activities running and coordinates resources.
- Documentation specialist — Records actions, outcomes, and lessons for after-action reviews.
At Riverbend Manufacturing, the disaster recovery team assigned and practiced these roles ahead of time. So when flooding kept a senior manager from reaching the facility, a designated alternate stepped in without hesitation. While the incident commander directed the overall response, the safety officer oversaw the evacuation, and the IT manager—acting under the operations lead—activated the cyber response remotely. Because responsibilities were clear, Riverbend’s recovery didn’t stall when leadership was scattered.
5. Document critical systems and processes
A disaster recovery plan is only as strong as the documentation behind it. Teams need to record every vital system, application, piece of hardware, and core business process in detail and rank them by priority.
This inventory should encompass mission-critical and on-premises systems, the primary site and disaster recovery sites, and any off-site data center resources where critical data may reside. That inventory becomes the foundation for deciding what must be restored first and what can wait. Good documentation also includes where backups are stored, whether in a secondary data center, a cloud service, or even manual alternatives for essential functions.
Some critical systems to consider include:
At Riverbend Manufacturing, the team had already compiled a complete inventory of IT infrastructure, production equipment, and supply chain processes. Because this documentation was stored offsite and in the cloud, staff could access it even when the central facility was closed. Having that record in hand allowed Riverbend to quickly identify the most urgent systems to bring back online, rather than scrambling to recreate information during the crisis.
6. Put safeguards in place early
The best way to speed recovery is to reduce the damage in the first place. Robust data protection controls and disaster recovery solutions can shield your critical data and applications from common threats while addressing vulnerabilities before they can be exploited.
Prevention and mitigation strategies focus on strengthening your facilities, systems, and people so disruptions have less impact. Standard measures include physical protections such as flood barriers, raised equipment, fire suppression systems, backup power sources, digital safeguards like multi-factor authentication, frequent patching, and tested backup routines.
At Riverbend Manufacturing, these precautions paid off. Flood barriers kept critical machinery above rising water, while cybersecurity training and phishing simulations prepared staff to spot suspicious activity. Regular software updates and immutable data backups further limited the fallout, allowing recovery teams to act from a stronger starting point instead of rebuilding from scratch.
7. Set measurable recovery objectives
After documenting your systems and assigning clear roles, the next step is deciding how quickly each system must be restored and how much data loss can be tolerated. These targets form the backbone of your recovery strategy and guide investment in backups, staffing, and vendor support.
The most common metrics are:
| Metric | Description | Example |
| Recovery Time Objective (RTO) | The maximum acceptable downtime for a process or system. | Riverbend set payroll and customer orders to be restored within 24 hours, since employees and customers would be immediately affected if those functions lagged longer. |
| Recovery Point Objective (RPO) | The maximum acceptable amount of data (measured in time) that can be lost during disruption. | Riverbend allowed no more than 15 minutes of lost transaction data for financial systems, supported by frequent backups. |
| Work Recovery Time (WRT) | The time needed to validate and restore normal operations once systems are back online. | After restoring their order system, Riverbend needed three additional hours to validate orders, catch up on backlogged transactions, and confirm with customers. |
| Downtime Cost Estimate | A calculation used to balance the investment in faster recovery against potential losses. | Riverbend estimated that if production were halted for a full day, it would lose about $250,000 in delayed shipments and overtime costs. |
Restore Critical Operations Faster With the Disaster Recovery Plan Template
8. Build playbooks for different scenarios
No single plan can cover every disruption, but disaster recovery should include scenario-specific playbooks. These are detailed guides for responding to specific incidents with a higher likelihood and/or severity. Each playbook should clarify who takes the lead, which procedures come first, what communication channels to use, and what contingencies are available if conditions worsen.
Common disaster scenarios worth preparing for include:
- Severe weather and flooding
- Cyberattacks such as ransomware or phishing intrusions
- Extended power outages
- Fire or hazardous material incidents
- Supply chain breakdowns
- Pandemics or large-scale health emergencies
- Earthquakes or structural damage
- Utility failures (water, HVAC, internet service)
- Civil unrest or security threats
- Transportation disruptions that affect critical deliveries
For technology teams, an IT disaster recovery plan functions as a scenario-specific playbook, providing the blueprint for quickly restoring systems and applications after an incident.
At Riverbend Manufacturing, teams activated two different playbooks when flooding forced an evacuation and ransomware hit their systems simultaneously. The IT team followed the cyber-incident plan—isolating infected servers, restoring from backups, and engaging vendors—while facilities managers switched to the flood response, arranging temporary workspaces and overseeing building repairs. Because these playbooks were already written and tested, the teams didn’t have to invent procedures during a crisis.
9. Know when to flip the switch
One of the biggest challenges in disaster recovery is deciding when an ordinary disruption has escalated into a full-blown emergency. Minor outages and delays happen frequently, and organizations can waste resources if they declare a disaster too early. On the other hand, waiting too long can compound the damage and make recovery far more difficult. That’s why every disaster recovery plan should define clear activation criteria: specific thresholds or triggers that signal when leaders should launch a plan.
Activation criteria are often tied to measurable conditions, such as the duration of a system outage, the severity of physical damage, or official warnings from emergency services. These benchmarks remove guesswork at a critical moment, ensuring everyone knows when to act. This guidance speeds up the decision-making process and prevents unnecessary hesitation during a crisis, when hesitation can be costly.
Riverbend Manufacturing relied on this kind of structure during its dual crisis. Leadership had already determined that floodwaters reaching a certain depth in the facility would automatically trigger their disaster recovery plan. At the same time, the IT team had thresholds in place for system alerts, so when ransomware locked their core servers beyond a set tolerance, the cyber playbook went into effect. Because those triggers were predefined and widely understood, the team could move decisively and begin recovery immediately rather than losing precious hours debating the severity of the situation.
10. Build your network of recovery resources
Identifying and managing the people, processes, tools, and supplies you need ensures you aren’t scrambling during a crisis. A clear inventory of these resources, updated vendor agreements, and service-level commitments allow recovery teams to act quickly and confidently when disruption occurs.
Maintain up-to-date contact information for all critical vendors, service providers, and external partners so that you can reach them quickly in a crisis.
| People | Processes | Tools | Supplies |
|
|
|
|
11. Keep work moving with alternate facilities and remote options
When your primary location is unavailable, the ability to shift quickly to alternate work arrangements can mean the difference between a temporary disruption and a complete standstill. This may involve leasing temporary office space, partnering with neighboring businesses, or activating pre-assigned warehouse or production sites. Increasingly, remote work is also a vital part of continuity planning, allowing employees to stay productive even if physical facilities are damaged or inaccessible.
For Riverbend Manufacturing, this flexibility was critical. Production floor staff could not return to the facility during the flood, but administrative and support teams switched immediately to remote work. Because the company had already invested in cloud-based systems and secure VPN access, employees could process orders, manage payroll, and communicate with vendors from home. Meanwhile, alternate warehouse space, identified in advance as part of the checklist, allowed limited production and distribution to continue while the main site was being repaired.
By planning for both physical alternate facilities and virtual work continuity, Riverbend avoided the kind of prolonged shutdown that could have cost customer trust and significant revenue. Having these options ready in advance ensured that the disaster did not halt every aspect of their operations at once.
12. Protect physical and digital records
Vital records are often the first casualty in a disaster, yet they are also among the most important to safeguard. Protection should account for physical and digital formats, ensuring critical information remains accessible and intact regardless of the disruption. These backup systems can involve storing paper documents in waterproof or fireproof containers, creating off-site archives, and maintaining multiple secure copies of digital data.
Digital resilience depends on more than just frequent backups. Encryption protects sensitive information if systems are compromised, while immutable storage prevents data from being altered or deleted. These measures preserve integrity and support compliance requirements, especially in highly regulated industries.
Riverbend Manufacturing took a layered approach. Essential contracts and compliance records were stored in waterproof cabinets, while encrypted financial and production data backups were automatically sent to a secondary data center. When flooding coincided with a cyberattack, both sets of protections held, allowing the company to access what it needed to recover without worrying about lost or corrupted information.
13. Keep communication clear and consistent
In any disaster, communication is as critical as restoring systems or facilities. A strong DR plan must cover how you’ll reach employees, customers, suppliers, and regulators during recovery. Relying on one channel is risky, so redundancy is key. Mass notification systems are especially valuable here, allowing you to push alerts through multiple channels and confirm who has received them.
Every plan should include pre-drafted messages for scenarios such as:
- Evacuation instructions for employees and contractors
- Notifications about facility closures or relocations
- System outage alerts with estimated resolution times
- Updates for customers on service delays or disruptions
- Guidance for suppliers on delivery changes or alternate contacts
- Health and safety advisories (e.g., weather hazards, contamination risks)
- Regulatory notifications or compliance updates
- All-clear messages signaling that normal operations have resumed
These elements form part of a comprehensive disaster communication plan, ensuring you reach every stakeholder during recovery.
When Riverbend Manufacturing faced simultaneous flooding and a ransomware attack, the communication coordinator used the company’s mass notification system to send evacuation instructions to staff, outage alerts to leadership, and service delay updates to customers and suppliers. Because the team had prepared templated messages in advance, they avoided confusion and maintained trust even while business operations were under strain.
14. Train, test, and refine the plan regularly
A disaster recovery checklist only works if the people responsible for it practice using it. Training and regular disaster recovery testing ensure that staff are comfortable with their roles and that the plan is more than just a document on a shelf. Organizations often start with a disaster recovery tabletop exercise, where leaders and key team members walk through hypothetical scenarios in a structured discussion. These tabletop exercise scenarios can uncover oversights, gaps in coordination, or unclear responsibilities long before an actual crisis.
There are several types of disaster recovery tests, each designed to build confidence in different aspects of your plan:
- Tabletop exercises — Low-disruption discussions where teams walk through a hypothetical scenario to evaluate decision-making, communication, and coordination. Best for identifying gaps in planning without interrupting operations.
- Functional tests — Focused drills that test specific recovery procedures, such as restoring a database from backup or switching communication channels. These validate that individual components of the plan work as intended.
- Full-scale simulations — Comprehensive exercises that mimic a real disaster, involving multiple teams, facilities, and systems. While resource-intensive, these drills provide the clearest view of how recovery will play out under pressure.
- Failover tests — Shifting critical operations to alternate infrastructure (such as a secondary data center or cloud environment) to ensure systems can run reliably if the primary environment is unavailable.
Most organizations start with tabletop and functional exercises, then build toward full-scale and failover tests once they have a mature plan in place. Using a variety of test types ensures that both leadership decisions and technical systems are equally prepared for disruption.
More advanced testing can take the form of simulations or live drills, such as restoring data from a backup, switching systems to a failover site, or conducting a full-scale facility evacuation. While disruptive, these exercises provide invaluable insight into how recovery measures perform under real-world conditions. An after-action report should follow each test to capture what worked, what failed, and how processes can improve.
Riverbend Manufacturing relied heavily on this cycle of practice and review. Twice a year, they ran tabletop exercises exploring scenarios like IT outages and supply chain disruptions, paired with emergency evacuation drills to test how quickly staff could move to alternate workspaces. After each exercise, leadership documented the results in a formal after-action report, refining their disaster recovery checklist with more precise communication steps and faster validation procedures. This commitment to continuous improvement meant that when a real disaster struck, employees didn’t hesitate—they had already rehearsed their roles.
Best practices in disaster recovery testing
- Use multiple test types (tabletop, functional, full-scale, failover).
- Involve all departments with role-specific responsibilities.
- Document results with thorough after-action reports.
- Update the plan based on lessons learned.
- Review and retest after any significant business or technology change.
- Treat regular testing as continuous improvement, not a one-time exercise.
15. Restore operations and transition back to normal
Restoration, often called failback, involves re-establishing primary systems, repairing or rebuilding damaged infrastructure, reconnecting supply chains, and winding down temporary workarounds. This step ensures that the business not only survives the crisis but also returns to a sustainable operating rhythm.
For Riverbend Manufacturing, the path to restoration began as floodwaters receded and they secured their IT environment. Employees returned to the main facility, recalibrated production equipment, and restored network services. As importantly, leadership documented every part of the disaster recovery process, updating the plan with lessons learned to prepare for the future.
Organizations may also align these efforts with their emergency operations plan, coordinating with local agencies and broader response frameworks. Pairing your disaster recovery strategy with a business continuity plan checklist helps maintain essential operations while recovery efforts are underway.
Ready to Put Your Plan Into Action?
While the story of Riverbend Manufacturing is hypothetical, it reflects challenges that many organizations face in real life. Floods, cyberattacks, power failures, and supply chain disruptions can strike at any time, and an effective disaster recovery strategy requires planning, execution, and continuous improvement to stay ahead of these threats. Using templates and checklists helps structure the recovery process, ensuring no one overlooks critical steps. A disaster recovery checklist provides that structure, giving teams the confidence to act quickly and restore business stability.
Disaster Recovery Plan Template
Prepare for and recover from any critical event your business may face.
AlertMedia, Risk Intelligence and Response



